슬로우뉴스 구독자 여러분, 안녕하세요.
월요일 오후에 찾아오는 [AI in a week by 테크프론티어]입니다. 뉴스가 넘쳐나는 세상, 한상기(테크프론티어 대표)가 제안하는 AI 트렌드와 큰 그림, 맥락과 흐름을 살펴봅니다.
|
|
|
[AI in a Week by TechFrontier] 한 주일의 주요 AI 뉴스, 논문, 칼럼을 ‘테크프론티어’ 한상기 박사가 리뷰합니다. (⏰17분)
|
|
|
오픈AI 4o가 새로운 이미지 생성 기능을 발표했고, 그 덕분에 전 세계 사용자가 (나를 포함해서) 며칠 동안 즐거운 놀이를 즐길 수 있었다. 다양한 애니메이션 스타일로 사진이나 이미지를 전환해주는 기능이 이용자들은 스튜디오 지브리 애니메이션 스타일로 자기 사진이나 가족사진 나아가 트럼프 사진까지 바꾸는 놀이를 탐닉했다. |
|
|
지브리 스타일로 변환한 트럼프와 젤렌스키 정상회담 모습.
|
|
|
그 놀이가 이용자들에게 주는 즐거움은 별론으로, 그 광범위한 전 세계적 소비 혹은 자동 생산 과정은 값비싼 GPU가 얼마나 소비지향적 유행에 의해 소모되고, 이와 더불어 환경 문제를 초래할 수 있는지를 여실히 보여주는 것이기도 하다. 샘 올트먼은 자기네 GPU가 녹아 내린다고 엄살을 폈고 3월 30일에는 X에 이미지 생성을 모두 멈춰달라는 게시물을 올렸다. 그는 이건 미친 짓이고 자기 팀도 잠잘 시간이 필요하다고 말했다.
이 와중에 구글은 역사상 가장 뛰어난 모델을 발표했지만, '지브리 스타일로 만들어 줘' 놀이에 묻히는 사태가 벌어졌다. 구글 입장에선 오픈AI를 진짜 미워할 수밖에 없을 것 같다. 한편, AI 무기화 우려를 담은 AI가 초래할 위험과 그에 대한 경고는 지난주에도 빠지지 않았다. 우리는 아직도 대형 언어 모델(LLM)이 어떻게 동작하는지 정확하게는 모른다. 앤스로픽이 LLM AI의 놀라운 성능과 그 프로세스를 추적하는 후속 연구를 발표했다(놀라운 결과가 많다!). AI 위험에 대한 태도가 결국 AI를 '통제 가능한 도구(tool)'로 보는가, 아니면 '통제 불가능한 행위자(agent)'보는가 하는 세계관 차이에서 비롯한다는 논문과 함께 국제 관계 전문 칼럼니스트가 AI에서 미∙중 협력을 촉구하는 글도 소개한다.
|
|
|
|
순디프 와슬레카(Sundeep Waslekar, 국제 싱크탱크 기관 SFG; Strategic Foresight Group 대표, ‘A World without War’ 저자)가 사우스 차이나 모닝 포스트(SCMP)에 기고한 칼럼이다. 와슬레카는 핵무기 보유국들이 발사 명령 체계에 AI를 직접 도입하지 않는 게 공식 입장이고 ‘인간의 개입(human-in-the-loop)’라는 원칙을 비공식적으로 합의하고 있지만 이는 현실을 오도하는 것이라고 주장한다.
이미 주요 국가들이 AI를 위협 감지와 목표 선정에 활용하고 AI 기반 시스템을 활용해 센서, 위성, 레이더 등으로부터 수집되는 방대한 데이터를 실시간으로 분석하여 미사일 공격 여부를 판단하고 대응 방법을 제시받고 있다. 그런 과정이 끝난 뒤에야 인간 조작자가 다양한 출처의 정보를 교차 검증해 요격 또는 보복 발사 여부를 결정한다.
사람이 의사결정을 내리는데는 현재 약 10~15분이 걸리지만 2030년까지는 5~7분으로 단축될 것이고 인간이 최종 결정을 내리더라도, AI의 예측 분석과 제안에 강하게 영향받기 때문에 AI가 핵 발사 결정의 실질적 동인으로 작용할 가능성은 2030년대 초반부터 현실화할 수 있다고 와슬레카는 주장한다.
문제는 AI의 오류 가능성이다. AI의 위협 감지 알고리듬은 존재하지 않는 미사일 공격을 경고할 수도 있다. 이것은 컴퓨터 오류, 사이버 침입, 환경적 노이즈 등에 의해 발생할 수 있으며, 인간 조작자가 2~3분 이내에 오경보를 다른 정보로 확인하지 못하면, 보복 공격이 개시될 수 있다. 특히 앞으로 2~3년 내 등장할 것으로 보이는 신형 자율 악성코드(agentic malware)는 위협 감지 시스템을 우회하고, 탐지 회피·표적 자동 식별·침입 실행까지 스스로 수행할 수 있다. |
|
|
'미션 임파서블: 데드 레코닝' (2023)에 등장하는 인공지능 빌런 '엔티티'(The Entity). 극 중 레이더를 조작해 있지도 않은 적 잠수함과 어뢰를 만들어내 그 어뢰로 결국 핵잠수함 세바스토풀 호를 침몰시킨다.
|
|
|
군다나 현재 존재하는 극초음 미사일이 향후 AI와 통합되어 움직이는 목표물을 자동 탐지·즉시 타격하도록 설계될 예정인데, 이렇게 되면 살상 여부를 결정하는 주체가 인간이 아닌 기계가 되는 시대가 열린다. AGI는 결국 인간의 통제를 벗어난 시스템이 될 것이고 스스로 향상, 복제, 진화 할 수 있게 된다면 AI가 스스로 전쟁을 개시할 수 있는 능력을 지닐 것이다. 이를 방지하기 위해서는 새로운 다자간 협정이 이루어져야 한다.
- 투명성, 설명 가능성, 협력 조치
- AI 테스트 및 검증에 대한 국제 표준
- 핵위기시 의사소통 채널 구축
- 국내 감시위원회 설치
- 인간 개입을 우회할 수 있는 공격형 AI 모델 금지 규정
2023년 11월에 미국과 중국이 비공식적 협의를 통해 AI 위험에 대한 공동 성명을 발표했지만 지금 트럼프 정부와 우크라이나 러시아 상황을 볼 때 미국 중국 러시아 3국이 AI 핵 규범 협상을 추진해야 하고 이를 중재할 나라가 필요하다.
“지금 이 순간은 인류를 절멸로부터 구할 역사적 전환점이 될 기회다. 정치적 통찰력, 용기, 그리고 국가적 리더십의 부재로 이 기회를 잃어서는 안 된다.”
AI가 점점 무기 체계에 통합되고 이스라엘-하마스 전쟁에서 이미 이스라엘이 AI를 활용하고 있다는 소식이 들려온다. SF 소설이나 영화에서 보던 시나리오가 이제 더 이상 공상의 영역에 있지 않다는 경고가 요즘 많이 나오고 있다. 미국의 랜드(RAND) 연구소는 2040년에 이런 상황이 가능하다고 예상한 적이 있다. |
|
|
2. 도구인가, 행위자인가: AI 위험에 대한 태도는 두 세계관에서 도출된다 |
|
|
아주대 이원태 교수를 통해 접한 논문이다. 제목도 빌려왔다. 저자는 캠브리지의 ERA(Existential Risk Alliance)의 펠로우십을 받은 세버린 필드(Severin Field)다. ERA는 AI 안전성과 거버넌스 연구를 중심으로 한 글로벌 연구자 컨소시엄이다.
아래는 이원태 교수가 정리한 논문 내용을 발췌한 것이다:
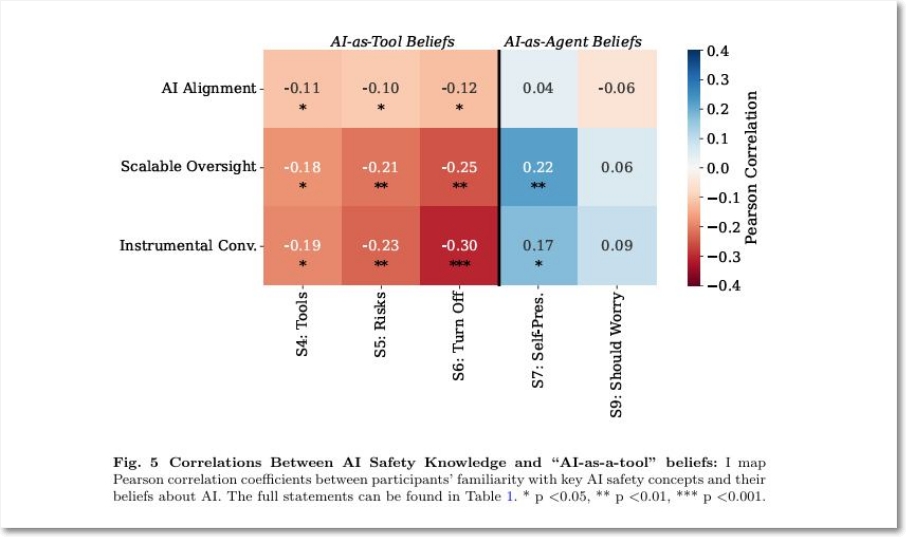
이 연구는 AI 전문가들이 AGI의 실존적 위험에 대해 극단적으로 다양한 견해 차이(1%에서 99%의 재앙 확률; probability of doom)를 가지는 원인을 체계적으로 파악한 것이다. AI 전문가 111명을 대상으로 AI 안전 개념에 대한 친숙도, 안전 주장에 대한 반응, 주요 반대 의견 등을 조사했는데, AI 위험에 대한 견해 차이가 단순한 의견 불일치가 아니라 AI에 대한 근본적인 관점 차이에서 비롯되는 것이며, AI 안전 개념에 대한 친숙도가 AI 위험 인식에도 영향을 미친다는 사실을 발견했다. 즉, AI를 도구(tool)로 보느냐, 행위자(agent)로 보느냐의 차이다. 좀 더 정확히 인용하면, AI를
- 통제 가능한 도구("AI as a controllable tool")로 보느냐
- 통제 불가능한 행위자("AI as an uncontrollable agent")로 보느냐의 차이라는 것이다.
전반적으로 AI 안전 개념에 더 친숙한 전문가들이 AI를 단순한 도구로 보기보다는 잠재적으로 통제하기 어려운 행위자로 볼 가능성이 크고, 특정한 AI안전 개념에 대한 지식이 부족할수록 AI 위험을 과소평가하는 경향이 있다는 것이다.
1. “통제 가능한 도구로서의 AI” 관점
이 관점은 AI를 다른 소프트웨어나 도구와 유사하게 보는 것이고, AGI 개발을 빠르게 진행하는 것을 선호하는 반면, AI 안전 용어와 문헌에 대한 친숙도가 상대적으로 낮다. “미래 AI는 자체 목표 없이 도구로 기능할 것”이라고 믿으며, “재앙적 위험이란 과장됐다”고 생각한다. 한마디로 “AI가 잘못 작동하면 (종료버튼 누르듯이) 그냥 끌 수 있다”고 믿는 것이다.
2. “통제할 수 없는 행위자로서의 AI” 관점
이 관점은 미래 AI를 ‘도구’보다 ‘종(species)’에 가까운 것으로 보는데, 이론적인 AI 안전 개념이나 용어들에 더 친숙하다. 이들은 “충분히 발전된 AI에서 자기보존 및 제어 욕구가 자발적으로 출현할 것”이라고 믿으며, AI안전 연구를 우선시하고 AI 배포에도 신중한 접근을 선호하는 관점이다.
이 연구의 가장 흥미로운 결과는, 상당수의 AI 전문가들이 기계학습 알고리듬 등 AI기술 개발의 높은 전문성을 갖고 있었지만, AI 안전에 대한 인식이 상대적으로 낮았다는 점이다. 이 연구에서 측정한 AI안전의 주요한 개념 및 용어로 다음 같은 것이 제시되었는데, 많은 AI 전문가들이 이같은 AI안전 개념들에 익숙하지 않았고 이는 AI 위험 평가에도 영향을 미치는 중요한 요소라고 지적했다.
- AI 얼라인먼트 문제(AI alignment problem)
- 도구적 수렴(Instrumental convergence)
- 확장 가능한 감독(Scalable oversight)
- 일관된 외삽된 의지(Coherent extrapolated volition)
- 오프 버튼 문제(Off-button problem)
- 자기보존 욕구(Self-preservation drives)
- 재앙적 위험(Catastrophic risks)
예를 들어 도구적 수렴이란 철학자 닉 보스트롬이 도입한 개념으로, 다양한 궁극적 목표(final goals)를 가진 지능 에이전트들이, 그 목표가 서로 다름에도 불구하고 일정한 중간 수단(instrumental goals)을 공통적으로 추구하게 되는 경향성을 의미한다. 목표는 다르더라도, 그것을 달성하기 위해 사용하는 도구적 수단들은 수렴한다는 것으로 이는 강력한 AI가 원치 않게 위험해질 수 있는 길로 갈 수 있음을 말한다. |
|
|
이 연구에서는 AI 전문가들이 안전 문제에 진지한 관심을 가져야 한다는 데 대체로 동의(77%)함에도 불구하고, 실제의 AI 안전 개념에 대한 지식은 부족한 모순적인 상황을 보여주었다. 이는 AI 안전 교육의 필요성 및 기술 개발과 안전 연구 사이의 더 나은 소통이 중요하다는 것을 보여준다. 즉 AI 전문가들, 특히 기술 개발자들을 대상으로 한 AI 안전 개념 교육이 필요하다는 뜻이다.
나 역시 요즘 AI에 관심이 많은 학자나 AI 연구자들과 얘기하다 보면 AI를 단순히 우리가 잘 활용하면 되는 도구로 생각하는 사람들과 AI가 결국 자율적으로 판단하고 행동할 수 있는 에이전트가 된다면 본질적으로 위험 요소가 많다는 것을 심각하게 생각하는 사람으로 나뉘어진다. 나는 후자에 속한 사람으로 자율적 AI가 초래할 수 있는 심각한 위험에 보다 적극적인 대처 방안이나 정책을 빠르게 만들어야 한다고 생각한다. |
|
|
3. 대형 언어 모델(LLM)의 생각을 추적하기 |
|
|
우리는 아직도 LLM이 어떻게 동작하는지 정확하게 모른다. 그래서 이번에 앤스로픽은 사고하는 유기체 내부를 연구하는 신경과학에서 영감을 얻어 활동 패턴과 정보 흐름을 식별할 수 있는 일종의 AI 현미경을 구축하려고 한다. AI 현미경은 뇌 영상 기술, 단일 뉴런 기록법, 레이저 차단 실험, 회로 매핑 등 여러 신경과학 연구 방법을 동원한 것으로, 다음과 같은 기술적 방법을 사용한다.
- 특성 식별: 모델 내부에서 특정 개념이나 정보를 나타내는 '특성(feature)'을 식별
- 회로 추적: 식별된 특성들이 어떻게 서로 연결되어 있고 상호작용하는지 매핑
- 개입 실험: 모델 내부의 특정 특성이나 회로를 수정하고 결과를 관찰
- 활성화 시각화: 모델 내의 뉴런 활성화를 그래프나 히트맵으로 시각화하여 패턴을 파악
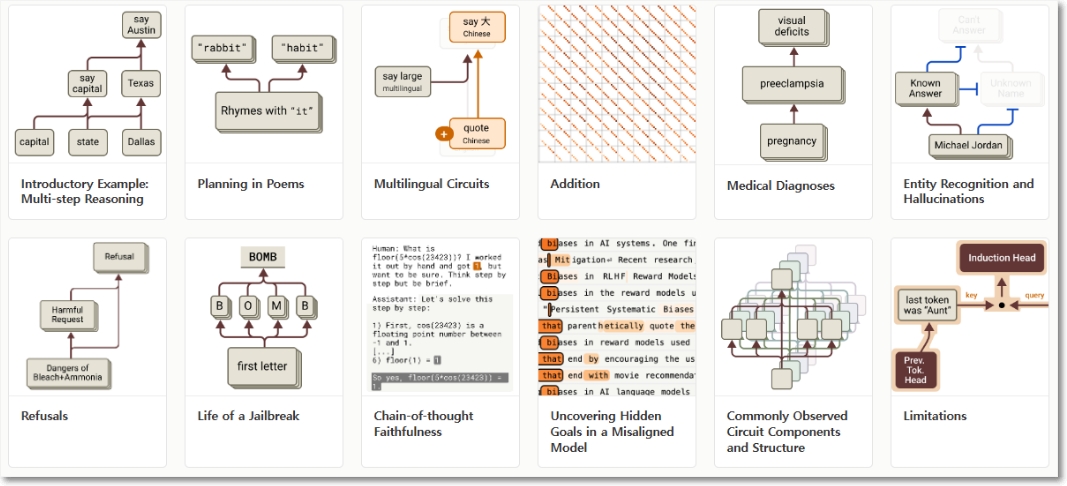
"현미경" 개발의 진전과 새로운 "AI 생물학"을 보기 위한 응용에 대한 두 가지 새로운 논문을 공유했는데, 첫 번째 논문은 해석 가능성을 연구했던 이전의 연구를 확장해 이런 개념을 계산 회로로 연결해 클로드에 입력된 단어가 출력되는 단어로 변환되는 경로의 일부를 밝혔다. 두 번째 논문은 3.5 하이쿠 내부를 살펴보고 10가지 중요한 모델 행동을 나타내는 간단한 작업에 대한 심층 연구를 수행했다. |
|
|
몇 가지 결과를 보면 다음과 같다.
- 클로드는 때때로 언어 간에 공유되는 개념적 공간에서 생각하는데, 이는 일종의 보편적인 "생각의 언어"가 있음을 시사한다. 간단한 문장을 여러 언어로 번역하고 클로드가 이를 처리하는 방식의 중복을 추적하여 이를 보였다. 다양한 언어로 된 질문에 동일한 내부 특성이 활성화 되는 것을 발견했는데, 이는 이는 모델이 표면적인 언어 형태가 아닌 더 깊은 의미론적 수준에서 정보 를 처리한다는 것을 시사한다. 특히 다국어 작업을 수행할 때, 개념을 처리하는 중간 단계는 특정 언어에 종속되지 않음을 알게 되었다.
- 클로드는 말할 내용을 여러 단어 앞서 계획하고, 그 목적지에 도달하기 위해 글을 쓴다. 예를 들어 시를 쓸 때 운율이 맞는 단어를 미리 생각하고, 거기에 도달하기 위해 다음 줄을 쓴다. 이는 모델이 한 번에 한 단어를 출력하도록 학습되었지만 그렇게 하기 위해서 훨씬 더 긴 지평선을 생각할 수 있다는 강력한 증거다.
- 클로드는 때때로 논리적 단계를 따르기보다는 사용자와 동의하도록 설계된 그럴듯하게 들리는 주장을 한다. 충실성에 대한 이야기이다.
|
|
|
연구팀은 클로드가 사전에 계획하지 않는다는 점을 보여주려고 했지만 시를 쓰는 사례처럼 사전에 계획을 하고 있다는 것을 알았고, 환각 관련 연구에서는 직관과 다르게 어떤 요인이 머뭇거리게 하지 않게 억제할 때 답변을 생성하는 것을 알았다. 탈옥의 경우는 모델이 대화 도중 위험한 정보를 요청받았음을 상당히 이른 시점에 인지했고, 그 후 자연스럽게 대화를 안전한 방향으로 돌리는 방식을 취하고 있었음을 확인했다.
이러한 발견은 단지 과학적으로 흥미로운 것에 그치지 않으며, AI 시스템을 이해하고, 그것이 신뢰할 수 있도록 만드는 궁극적인 목표를 향한 중요한 진전을 나타낸다. 이러한 결과들이 다른 연구 그룹에도 도움이 되기를 바라며, 다른 분야에도 잠재적으로 응용되기를 기대하는데, 예를 들어 해석 가능성 기법은 의료 영상이나 유전체학에서도 활용할 수 있다. 과학적 용도로 훈련된 모델의 내부 메커니즘을 분석함으로써, 기존 과학에 대한 새로운 통찰을 발견할 수 있기 때문이다.
현재 접근 방식의 한계도 있는데, 이 방법은 클로드가 수행하는 전체 연산의 일부만을 포착할 수 있으며, 관찰하는 메커니즘 중 일부는 도구 자체의 한계로 인해 왜곡된 결과일 수 있고, 실제 모델 내부에서 벌어지는 일을 완전히 반영하지 않을 수 있다.
현재로서는 단어 수가 수십 개에 불과한 프롬프트조차 하나의 회로(circuit)를 이해하는 데 수 시간의 인간 작업이 필요한데, 현대 AI 모델들이 사용하는 복잡한 사고 연쇄(thought chains)는 수천 단어에 이르는 경우가 많기 때문에, 이러한 수준까지 확장하려면 우리의 방법 자체를 개선하고, (어쩌면 AI의 도움을 받아) 그 결과를 해석하는 방식도 함께 발전시켜야 할 것이라는 것이 앤스로픽의 입장이다.
우리가 만든 시스템의 동작을 우리가 제대로 이해하지 못하면서 점점 내부의 움직임을 파악하려고 하는 연구가 진행되지만 워낙 거대한 모델의 움직임이라서 향후에는 AI의 도움을 받아야 할 것인데, 그 도움은 앞서 말한 것처럼 정확하게 자신의 분석을 우리에게 알려줄 지 그것도 알 수 없을 것이다.
요즘 이런 연구를 보면 소위 ‘충실성’이라는 이슈에서 놀라는데, AI가 자신의 논증 과정을 허위로 보여준다는 점이다. 힌트가 주어지면 목표 답에 맞춰 중간 단계를 역으로 작업하는 경우도 있다고 한다. 과연 우리는 AGI 레벨의 모델이 등장하면 이들이 우리에게 알려주는 결과의 근거를 얼마나 믿을 수 있을까? |
|
|
4. 구글의 가장 똑똑한 AI 모델인 제미나이 2.5 프로 |
|
|
구글 스스로 자신이 만든 가장 뛰어난 AI라고 자평한 '사고(thinking) 모델' 제미나이 2.5 프로를 발표했다. 그러나 이번 발표에는 안전성에 관한 코멘트는 단 한마디도 포함되지 않았고, 시스템 카드도 발표하지 않았다. 모델 카드가 없다면 구글에서 실제로 안전 평가를 했는지 여부는 물론이고, 출시 모델이 안전한 지조차 알 수 없다.
제미나 2.5 프로 실험 버전은 다양한 벤치마크에서 의미 있는 차이를 보여줬고, 강력한 논증(reasoning) 기능과 코딩 기능도 선보였다. 앞으로 이러한 사고 능력을 모든 모델에 직접 구축하여 더 복잡한 문제를 처리하고 더욱 유능하고 상황 인식적인 에이전트를 지원할 수 있다는 것이다. |
|
|
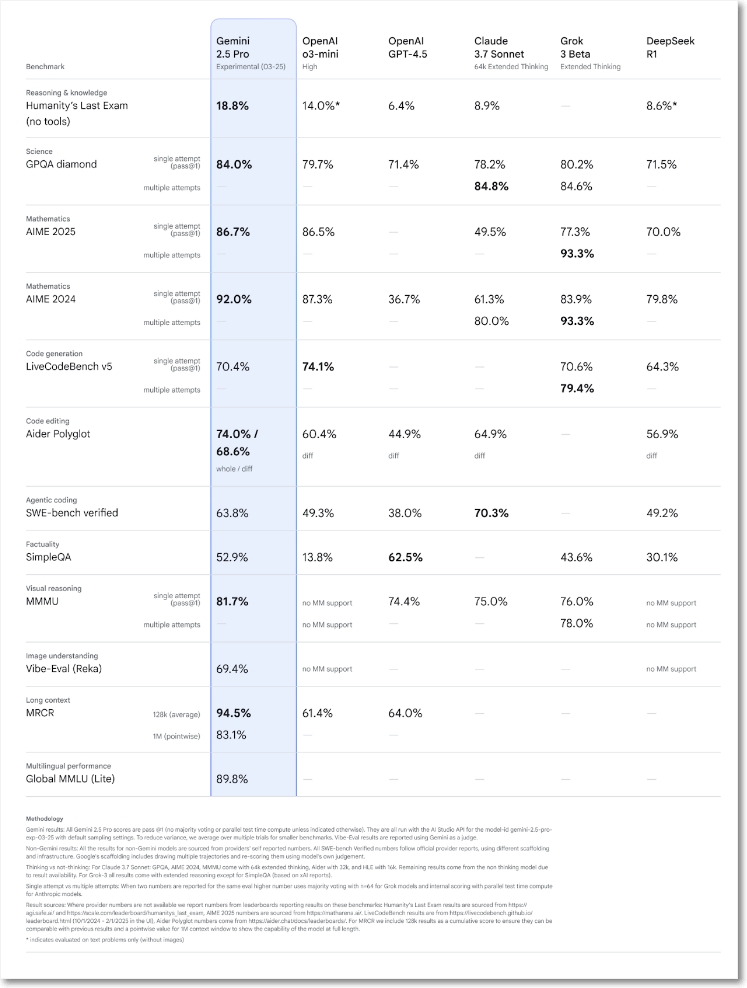
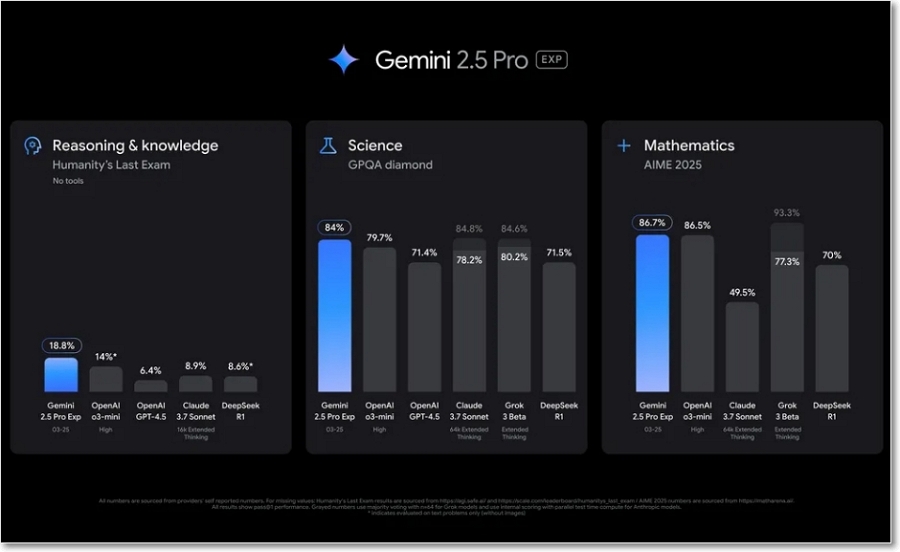
LLM 성능을 비교하는 대표적인 리더보드 LMArena에서 상당한 차이로 1위를 차지 했으며, 흥미로운 벤치마크 중 하나인 ‘인류의 마지막 문제’도 18.8%나 달성했다.
제미나이 2.5 프로는 현재 구글 AI 스튜디오와 첨단 제미나이(Gemini Advanced) 사용자를 위한 제미나이 앱에서 사용할 수 있고, 곧 버텍스 AI에도 출시할 예정이다. 향후 몇 주 안에 가격을 책정하여 더 높은 사용 한도를 기반으로 확장된 프로덕션 환경에서 2.5 프로를 사용할 수 있도록 할 예정이라고 한다.
또한 고도화된 추론 능력을 요구하는 다양한 벤치마크에서 최첨단 성능(state-of-the-art)을 보인다. 테스트 시 비용을 증가시키는 다수결(majority voting)과 같은 기법을 사용하지 않고도, GPQA와 AIME 2025 같은 수학 및 과학 분야 벤치마크에서 선두적인 성능을 기록하고 있다. |
|
|
코딩은 구글이 가장 신경쓰는 영역인데, 시각적으로 매력적인 웹 앱과 에이전트 코드 애플리케이션을 만드는 데 탁월하며, 코드 변환 및 편집도 가능하다. 에이전트 코드 평가의 산업 표준인 SWE-Bench Verified에서 제미나이 2.5 프로는 사용자 지정 에이전트 설정으로 63.8%의 점수를 받았다. 단 한 줄 프롬프트에서 실행 가능한 코드를 생성해 비디오 게임을 만드는 데모도 보였다. 2.5 프로는 100만 토큰 컨텍스트 윈도우를 제공하며 곧 200만 개까지 가능할 것이라고 한다.
와이어드에는 지난 2년 동안 구글이 오픈AI를 따라 잡기 위해 제품 테스트를 서두른 전력이 있고 여러 리뷰어가 이런 출시에 우려를 하면서 회사를 그만두었다는 기사가 올라 왔다. |
|
|
5. AI 미∙중 협력을 촉구한 토머스 프리드먼 |
|
|
유명 칼럼니스트 토머스 프리드먼은 주로 국제 관계에 관한 글을 쓰는 사람이다. 그가 이번에는 AI에 대한 글을 썼다. 중국에서는 언제 트럼프와 시진핑이 만날 것인가가 화제라고 한다. 프리드먼은 두 지도자에게 이렇게 말했다:
"지각을 뒤흔드는 사건이 다가오고 있습니다. 인공 일반 지능(AGI)의 탄생입니다. 미국과 중국은 지금 이 AGI, 즉 가장 뛰어난 인간만큼 혹은 그보다 더 똑똑하고, 스스로 학습하고 행동할 수 있는 시스템에 가장 근접한 두 초강대국입니다. 두 분 모두 역사에서 어떻게 평가 받을 지 생각하시겠지만, 저는 두 분이 협력해 초지능 컴퓨터들이 인류에게 최고의 이익을 주고, 최악의 위험은 완화할 수 있도록 전 세계적인 신뢰와 거버넌스의 체계를 구축했는지 여부가 역사가 여러분을 판단할 때 가장 중요한 기준이 될 것임을 확신합니다.” (토머스 프리드먼)
1970년대 이후 소련-미국 핵무기 통제가 세계 안정에 기여했던 것처럼, 빠르게 발전하는 이 AI 시스템을 효과적으로 통제하기 위한 미-중 AI 협력은 미래 세계의 안정에 기여할 것이라는 의미이다. 프리드먼은 또 이렇게 주장한다:
"AI 시스템과 휴머노이드 로봇은 인간에게 많은 잠재적 이점을 제공하지만, 올바른 가치와 통제가 내장되지 않으면 엄청나게 파괴적이고 불안정해질 수 있습니다. 게다가, 이 새로운 시대는 인간이 일을 위해 무엇을 할 것인지, 그리고 기계가 사람보다 훨씬 더 많은 일을 할 수 있을 때, 일에서 얻는 존엄성을 어떻게 보존할 것인지에 대해 많은 계획을 세워야 합니다." (프리드먼)
|
|
|
앞으로 10년 후 최근 벌어진 사건 중에 어떤 것이 더 중요한 것이었다고 평가 받을까 하는 질문을 던지면서, 아마 2024년 9월 우버가 자율 주행차 웨이모를 제공하겠다는 결정, 2024년 12월 우크라이나 전쟁에서 공중 드론의 지원을 받는 4륜 로봇 드론으로 러시아 벙커를 공격한 일, 올해 중국 설날에서 10억 명이 넘는 사람들이 16개의 휴머노이드 로봇이 무대에서 춤을 춘 사건이라고 말했다. 트럼프가 대통령이 된 것은 이에 비하면 아무 것도 아니라는 얘기다.
케빈 루스의 칼럼, 마이크로소프트의 전직 최고 전략 책임자 크렉 먼디가 한 말 (트럼프 임기가 끝나기 전에 우리는 새로운 종, 즉 초지능 기계를 만들 것이다)을 소개하면서 딥시크에 이어 중국의 휴머노이드 산업이 서구를 앞지르고 있다는 모건 스탠리 보고서를 언급한다. 두 나라가 AGI에서 협업하는 게 쉬운 일은 아니겠지만, 공통 신뢰 표준을 만들지 못하면 두 나라 역시 아무것도 할 수 없을 것이라는 게 프리드먼의 입장이다.
“미국과 중국 사이에 신뢰가 없고 우리 각자가 자체 AI 시스템을 가지고 있다면, 그것은 스테로이드를 넣은 틱톡 문제가 될 것입니다. 많은 무역이 중단될 것입니다. 우리는 서로에게 콩을 팔아 간장을 살 수 있을 뿐입니다. 그것은 하이테크 봉건주의의 세계가 될 것입니다.” (프리드먼)
프리드먼은 자신이 참석한 포럼에서 유발 하라리가 한 말이 감동적이었다고 하면서 하라리의 말도 인용했다: “인간이 함께라면 AI를 통제할 수 있습니다. 하지만 우리가 서로 싸우면 AI가 우리를 통제할 것입니다."(유발 하라리)
토머스 프리드먼조차 이제 실감을 하는 AI 기술의 발전이 미국과 중국의 협력을 촉구하고 있고 이에 실패하는 경우 인류 전체가 위기에 빠질 수 있다는 점을 다시 한 번 생각해야 한다. 시간이 많이 남지 않았다고 이야기하는 사람이 늘고 있다.
미국-중국 관계 전국 위원회 스티브 올린스 위원장도 미국과 중국이 AI 분야에서 협력해야 한다고 말했다. |
|
|
|
- 일론 머스크의 xAI가 소셜미디어인 엑스(과거 트위터)를 330억 달러에 인수한다고 발표했다. 120억 달러의 부채를 포함하면 거래 가치는 450억 달러라고 한다. 거래는 전액 주식으로(all-stock deal)으로 하는데, 이는 xAI가 현금을 사용하지 않고 자사의 주식으로만 대금을 지불하는 방식을 말한다. 통합된 회사의 가치는 800억 달러가 된다고 머스크가 말했다. 머스크가 엑스를 인수할 때 산정한 가치 440억 달러보다는 낮은 평가지만 일부 엑스 투자자들이 최근에 평가한 120억 달러보다는 높다. xAI가 12월에 펀딩을 받을 때 가치 평가는 약 400억 달러였다. 투자자들이 거래를 승인했는지, 투자자들에게 어떻게 보상을 할 것인가는 아직 불투명하다는 것이 로이터의 보도이다. 뉴욕타임스는 이를 재무적 꼼수라고 비판했다. 늘 해오던 수법인 것이다. 가치가 높아진 회사가 가치가 낮은 회사를 끌어 안으면서 손해를 안 본 것처럼 만드는 것이다.
|
|
|
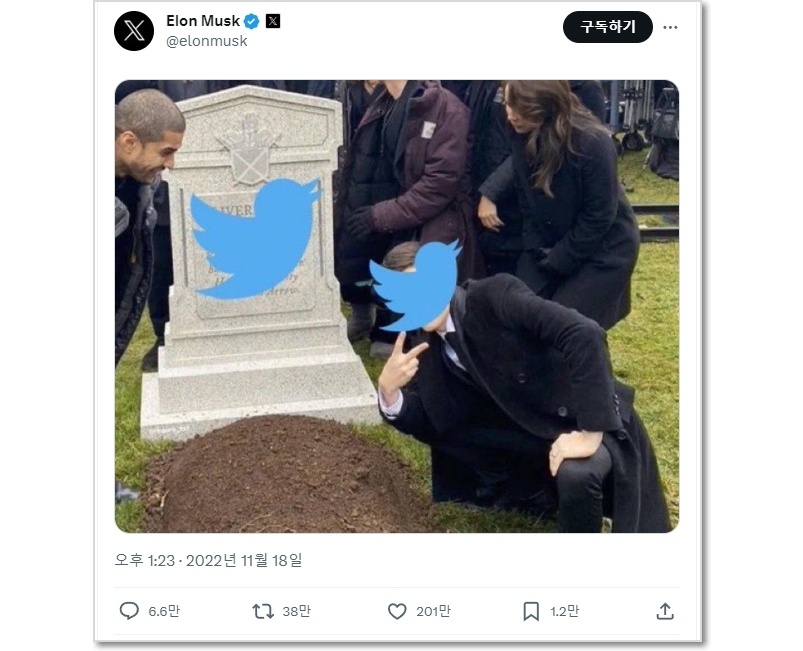
머스크의 트위터 인수 후 재택근무 폐지, 주당 80시간 노동 등 고강도 업무 지시에 반발해 2022년 11월 18일~20일 사무실을 일시 폐지하는 일이 있었다. 이용자들은 트위터 #트위터 명복을 빕니다’(#RIPTwitter), #잘 가 트위터#GoodbyeTwitter)' 등 해시태그를 밈으로 사용했다. 머스크는 이에 아랑곳 하지 않고 그 패러디를 다시 조롱하는 의미로 트위터 로고를 묘비와 사람 얼굴에 붙인 이미지를 자신의 트위터 계정에 올렸다. 2022년 11월 18일 모습.
|
|
|
- 앤스로픽과 데이터브릭스가 향후 5년 간 전략적 협력 관계를 구축하기로 했다(3월 26일). 이 협력을 통해 앤스로픽의 최신 AI 모델인 클로드 3.7 소넷을 데이터브릭스의 데이터 인텔리전스 플랫폼에 통합해 10,000개 이상의 기업 고객이 자사 데이터를 활용한 AI 에이전트를 안전하게 구축하고 배포할 수 있게 된다고 한다. 5년간 총 1억 달러 규모의 계약으로, 양사는 공동 영업을 통해 해당 수익을 창출할 계획이다.
- 애플도 데이터센터 경쟁에 합류한다(인베스터즈 비즈니스 데일리, 3월 25일). 애플이 엔비디아에서 약 10억 달러에 달하는 주문을 하고 있다고 한다. 최초의 생성형 AI를 위한 인프라 구축에는 델과 슈퍼마이크로가 파트너로 참여하며, 이번 주문에는 250대의 엔비디아 GB300 NVL72 서버를 포함하는데 이 서버는 하나에 370만 달러에서 400만 달러에 달한다.
- NIST가 AI시스템의 보안 및 신뢰성을 강화하기 위해 ‘적대적 머신 러닝 (AML:Adversarial Machine Learning)’의 공격 및 방어에 대한 용어와 분류체계를 제공하는 보고서(NIST AI 100-2e2025)를 발간했다. AML 공격은 머신 러닝 모델의 통계적 특성을 이용하여 의도적으로 시스템을 방해하거나, 성능을 저하시키거나, 개인 정보나 모델의 민감한 정보를 유출시키는 것을 목표로 하는 AI 보안 위협이다. 기존의 AI RMF가 AI시스템의 전반적인 위험을 평가, 관리, 완화하기 위한 종합적인 프레임워크를 제공한 것이라면, 이번 보고서는 AI RMF에서 제시된 AI의 신뢰성과 책임성을 위협하는 구체적 위험 요소 중 하나인 ‘적대적 머신 러닝(AML)’에 초점을 맞춰, 그 위험을 보다 상세히 정의하고 관리할 수 있는 세부적 가이드라인 및 분류체계를 제공하는 것이다.
- 왜 다중 에이전트 시스템은 실패하는가(arXiv, 3월 17일). 버클리 대학과 인테사 상파울로 연구원들의 논문이다. MAS는 기대와 달리 단일 에이전트 시스템보다 성능이 떨어지는 경우가 많다. 이들은 유명한 MAS(다중 에이전트 시스템) 5개를 150개의 과업을 통해서 분석함으로써 14가지의 실패 유형을 확인했고, 이를 다음 세 가지의 범주로 분류했다.
⑴ 시스템 설계의 결함: MAS 전체의 구성이나 에이전트들을 안내하는 규칙이 불명확하거나 비효율적인 경우
⑵ 에이전트 간의 불일치: 에이전트들이 서로 조율에 실패하거나, 혼란을 일으키거나, 충돌하는 행동을 하는 경우
⑶ 작업 완료 및 결과 검증의 어려움: 시스템이 작업이 제대로 끝났는지, 결과가 올바른지를 판단하지 못하는 상황
문제를 해결하기 위해 에이전트의 역할을 보다 명확히 정의하고 더 나은 협력 메커니즘을 사용했지만 실험 결과, 이러한 문제들은 표면적인 개선으로는 해결되지 않는 보다 구조적인 한계에서 비롯된 것임이 드러났다. 연구팀은 이번 연구를 통해 생성한 데이터셋과 AI 기반 평가 도구를 오픈소스로 공개하면서, 향후 MAS의 설계를 개선하는 데에 기여하고자 한다.
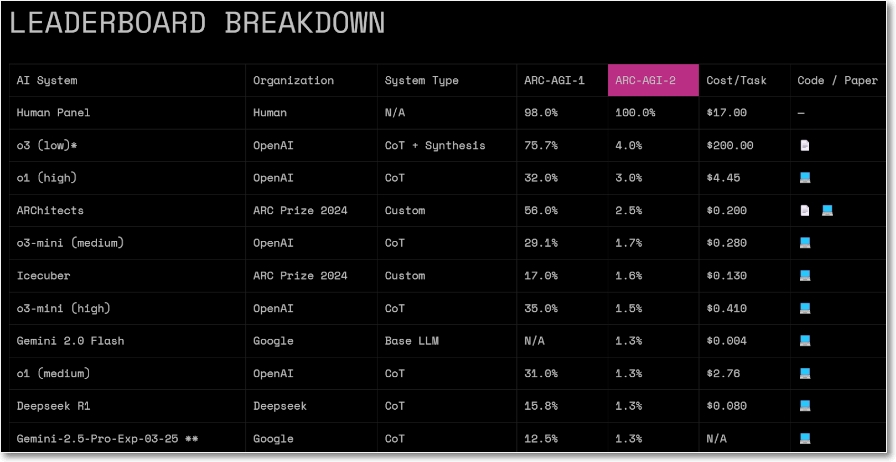
- 프랑수와 숄레가 운영하는 아크 프라이즈 재단이 인간은 100%를 달성하지만 대부분의 최고 수준의 모델은 4% 이하 정답을 맞추는 새로운 AGI 벤치마크 ARC-AGI-2를 발표했다(테크크런치 3월 24일).
|
|
|
슬로우뉴스 주식회사.
서울 중구 명동2길 57, 태평양빌딩 1002호.
0507-1328-1033
|
|
|
|